

校園一卡通系統挖掘學生異常行為淺析
文章出處:http://www.katarog.com 作者:吳慧韞 王河堂 人氣: 發表時間:2011年07月09日
當前,在高校擴招和學生隊伍總量不斷增大的背景下,高校學生異常行為的人數呈上升趨勢,一些違法、違紀、違俗、違德等異常行為時有發生,而學生管理工作者也往往因為學生異常行為發生前的“苗頭”把握不準,常常處于當“消防員”的被動局面。
如何利用現代化的手段對學生早期異常行為進行檢測與控制,幫助管理者及時發現有問題的學生,從而進行有針對性的教育與幫助,具有十分重要的意義。
一卡通數據來源
近年來,隨著計算機網絡和數據庫技術的日漸完善,國內不少大學都相繼建立了校園一卡通系統。校園一卡通系統是數字化校園的重要組成部分,它為數字化校園的建設提供了全面的數據采集和良好的信息共享環境。
該系統的開發建設將進一步提高信息化管理水平,實現由面向計算機的管理轉變為面向數據管理。而目前大多數高校僅僅停留在使用一卡通系統的基礎上,殊不知可在此基礎上建立數據倉庫系統,實現對各部門生成的大量數據的科學提取、凈化、存儲,從而使得信息系統滿足從業務處理到中層管理的控制,以及通過對各階段各部門的數據進行統計、分析、挖掘,最終達到為領導決策提供支持的目的。
校園一卡通系統一旦建成,它所采用的校園卡可替代現有的多種證件,包括:學生證、工作證、身份證、借書證、閱覽證、醫療證、會員證、就餐卡和錢包等。
校園一卡通系統的主要數據來源:
1.學生入校時填寫的各種登記表格、各學期注冊情況登記等相關文檔。
2.學生在食堂就餐時的劃卡記錄。
3.學生體檢情況、就醫情況的醫療記錄。
4.圖書館學生借書情況登記、進出圖書館閘機記錄等。
5.校內各種開放設施的劃卡消費情況記錄,如公共機房、校體育設施、校賓館飯店。
6.學生早鍛煉情況的記錄。
7.學生通過門禁系統出入各建筑樓宇的記錄。
這些數據均可以從數字化校園中的公共數據平臺及相關職能部門的信息管理系統中導出、匯總進入數據倉庫。
利用數據挖掘異常行為
數據的條件獨立性
一般說來,數據的獨立性包括條件獨立性、因果獨立性與上下文獨立性。這些獨立性關系,都對數據分析具有重要的作用。
條件獨立性是指在某些變量給定時,其他部分結點相獨立,因此只要找出特定的給定變量,即可為決策提供足夠的支持,這稱為條件獨立性。因果獨立性是指變量之間的直接影響,但是并沒有對如何依賴作出約束。一些情況下,多個變量相互合作,對某變量共同產生影響。但是,很多情況下,各變量獨自對其他變量起作用,原因變量之間沒有合作,此時原因變量對結果變量的影響是因果獨立的,這稱為因果獨立性。
通常每個變量都帶有條件概率標,在各原因變量狀態組合的每種取值情況下給出結果變量的每種取值的條件概率。條件概率表一方面需要的條件概率數目是原因變量結點數目的指數冪,另一方面無法捕捉原因變量概率分布的某些規律。這是第三種獨立關系,稱為上下文獨立性,通常可以采用條件概率樹的形式對上下文獨立關系進行表示。本文以條件獨立性為例,對一卡通的數據信息進行研究。
一般地,若變量E和F在G給定(p(G)≠0)時,滿足下列條件之一時是條件獨立的:
1. P(E|F∩G)=P(E|G) 且 P(E|G)≠0,P(F|G)≠0
2.P(E|G)=0 或 P(F|G)=0
基于條件獨立性的數據分析
為了提高有問題學生認定的準確率與有效性,針對一卡通的相關數據流進行以下幾個方面的分析:
1.根據學生入學時填寫的各種記錄表初步了解其基本情況。
2.通過分析長期的學生的金融消費數據以及樓宇身份認證等數據計算月平均開銷、出入教師或圖書館的頻率、早鍛煉的積極性等,給出認證偏低區間的實證結果。這可用來發現性格內向但不愿向師長和同學說明情況的學生。
3.根據校內各種開放設施的劃卡消費及認證情況記錄計算月平均開銷及各種活動的出勤情況。對于月開銷較大或出勤情況反常的學生應深入了解情況,杜絕個別學生思想臨時出現緊急波動的情況。
4.根據體檢情況、就醫情況的醫療記錄關注有問題學生的健康狀況。對于健康狀況較差的有問題學生應加大援助的力度。
5.根據上機情況、圖書館借閱情況及考試成績了解有問題學生的學習努力程度。
本文針對上述的第二條中的數據進行重點的數據挖掘,同時針對初步結果,再結合第一、三、四、五條進行聚類分析,試圖尋找到消費和認證行為的某些相關性及條件獨立性,從而有助于學校及早發現思想有問題的學生,為教師進行思想有問題學生決策提供更準確的數據支持。
一卡通信息的數據挖掘
1.數據準備:由于一卡通的流水數據中有許多龐大的價值較低的數據,因此,現有的一卡通流水數據必須經過數據的預處理后才能變成挖掘的對象。
(1)將卡流水交易數據庫分割成小的數據表。我們將校園卡流水交易數據庫分成若干張細表,每個表為一個月的數據,少則幾萬(假期),多則上百萬條記錄。
(2)通過卡號將存在于卡流水交易數據庫和用戶資料表的數據搜索出來,為數據挖掘提供數據源。
(3)計算屬性:由于集成幾個數據庫而得到的數據依然反映的是每次刷卡交易的記錄,實際情況是消費或認證可能在某處的一個或多個POS機上完成。因此需根據刷卡的時間進行分段求和,我們把一天分成三個時間段(0∶00~10∶00,10∶00~15∶00,15∶00~24∶00),在這三個時間段內的刷卡記錄分別歸為早、中、晚三個階段,因此對于每一個卡號用戶必須分別按這三個時段統計出三個階段的刷卡頻率。
本地學生周末通常不在學校,因此需要特殊處理;考試期間由于學業繁重,早鍛煉的頻率也將正常下降,此時也需要特殊處理。但為了分析結果的準確性,不能清洗任何刷卡記錄。
2.建立數據倉庫
采用Microsoft Analysis Services建立數據倉庫:首先新建數據倉庫DSS,數據源自于上述經過預處理的一卡通數據庫;然后建立多維數據集,將所有數據按月劃分為多個數據表,每個數據表建立一個多維數據集,選擇刷卡金額或認證次數為度量值,通過POS機具信息表、賬戶信息表、認證信息表建立維度表。
3.知識分析
根據一個月的情況,計算出每個學生的每月學習日的刷卡次數(X)。
這里我們定義以下幾個指標:每月學習日正餐消費次數(X)、每月學習日正餐最低消費次數參考值(M)、學習日正餐的一餐消費額(Y)、學習日正餐的一餐消費額參考值(N)。
若滿足X≥M,以及Y<N,可認定為是刷卡次數偏低的群體,這個群體組成一個集合。結合該群體的基本信息如生源地、性別、年齡、年級等分析其相關性。
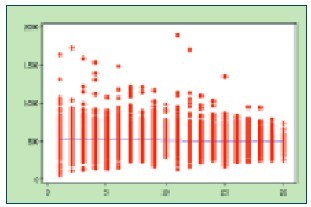
圖1 學生正餐消費次數與消費金額分布
圖1是學生正餐消費次數與消費金額分布圖示例。X軸為某月份(2010年9月份)學生正餐消費次數(除去每日早餐與周六、周日三餐),Y軸為該月正餐的一餐消費均值(單位為分),圖1抽樣數據為2010級所有學生(4150名)。管理者可以粗略地觀察消費均值集中分布區域,與消費次數集中分布區域。如需要進一步挖掘出低消費人群,需要在下文中進一步分析。
M和N是人為給定的,需要校方管理人員結合實情與經驗給出,比如上例中,我們假定為M=15次,N=5.00元,則通過X≥15次,N<5.00元,可以找到圖1中相應的消費偏低的群體。
以上僅是一種理想的狀況,在真實的分析中,有時需要根據不同的聚類來調整參數以得到不同的分析結果。比如:刷卡消費偏低群體中性別比例與實際在校生的性別比差別很大時,可能是學習日男女活動的頻率差異參考值導致,因為男女生有較大差異,需要調整。我們抽樣的數據可以進一步按性別進行聚類分樣。
最后,通過學生基本信息庫的關聯分析,我們可以進一步得到:刷卡消費偏低與家庭情況的相關性、刷卡次數偏低與校內其他開放設施的劃卡消費相關性、刷卡消費偏低與圖書館自習次數的相關性、刷卡消費偏低與就診次數的相關性等等,以此讓教師有更全面的判斷。例如對于刷卡消費偏低同時圖書館自習次數較多成績優秀的學生應給予助學補助及勤工助學機會。
對于刷卡次數異常的學生,說明思想出現了波動,例如經常不參加集體活動或經常在正常上課時間外出等。學校根據分析結果,找出這些行為異常的學生名單,便于校方進行重點的思想教育活動。
數字化校園及一卡通系統中所存儲的學生信息、一卡通數據,成為有問題學生的決策依據,這僅是數據挖掘在數字化校園中的一個簡單應用,如何把數據挖掘技術和數字化校園更好地結合起來,為高校的管理、建設決策提供更完備的支持是各大高校接下來面臨的一個現實問題。








